

최근에 'DW pose'를 리뷰한 것과 유사하게, 사람 관절을 추론하고 이를 활용하는 프로젝트를 수행하고 있기에, 관련된 연구를 찾아보고 있어서 공부 겸 정리하고자 한다. 파운데이션 모델이라고 불리는 많은 데이터로 큰 모델을 학습해서 배포하는 연구가 다양한 분야에서 연구되고 있다. 해당 연구는 어떤 의미에선 연구 보다는 엔지니어링에 가깝긴 하지만, 해당 연구를 통해 다른 연구 혹은 유사 연구에서 가능한 상한 성능을 볼 수 있는 점에서 의미가 있고, 또한 레이블이 어렵고 생각보다 다양한 영역에 활용될 수 있어서 가치가 있다고 생각한다. 해당 연구도 사람 포즈 추정 뿐 아니라, 의미 분할 및 깊이 추정, 표면의 법선 추정(surface normal)를 동시에 수행하고 있다. 본 블로그에서는 다른 내용 보다는 포즈 추정을 중심으로 다루고, 개요 및 선행연구는 생략하고 작성하고자 한다.
유사 주제의 블로그 글:
한 줄 평:
" 많은 사람 데이터를 활용해, 사람을 주제로 한 다양한 작업(task)을 수행하고, 최고 성능을 찍었다."
1 Method
1.1 Preliminaries
논문을 설명하기에 앞서, 간단한 노테이션을 정리해보면 실제로 사람의 전체 몸이 308개 정도의 관절을 갖고 있고 얼굴이 거의 대부분의 관절을 차지하는 걸 알 수있다.

신경망의 근간은 'masked-autoencoder(MAE)' 를 기본으로 하여, 각 작업을 수행하는데, 이에 따라 부분만 보이거나, 일부가 가려지더라도 충분히 관절을 예측하거나, 이미지를 잘 생성해내는 걸 알 수 있다.

1.2 2D Pose Estimation
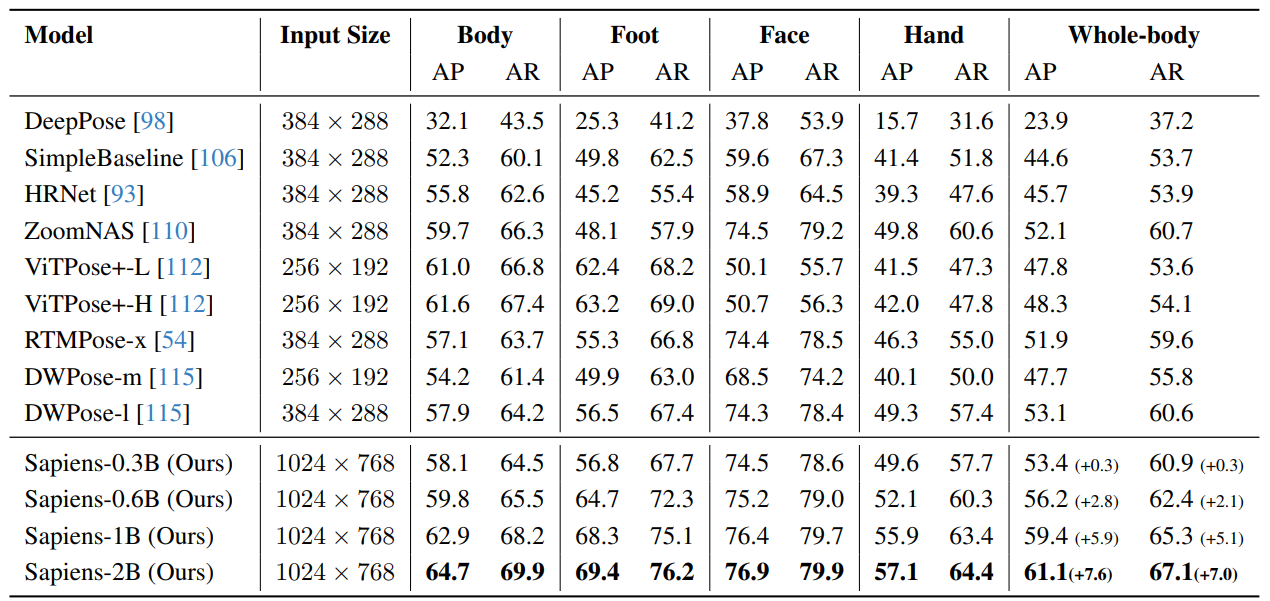
실제로 의미 분할, 포즈 추정, 이미지 복원 등 다양한 작업(task)을 수행하는 목적의 연구이긴 하지만, 내 목적은 관절 추정만 해당하기에, 이 챕터만 눈여겨 보았다. 논문에서 얘기하는 게, 기존 'RTMpose'나 'DWpose' 처럼 복잡한 KD(knowledge disillation)이나, X, Y로 각각 관절 위치를 설정해서 분류(classification) 문제로 푸는 등의 복잡한 구조없이 간단하게 성능을 높였다고 한다. 따라서, 손실함수는 $L_{pose}=MSE(y,\hat{y})$이다. 논문에서 충분히 설명되지 않아서, 실제 파라미터가 얼마나 차이가 나는 지 알 수 없어 아쉽다.
2 Experiments
개인적으로 흥미로웠던 실험만 선별적으로 다룬다.
TBD (Image)
3 Reference
제안 논문 및 관련 코드



